What is Data Science? Understanding Data Science from Scratch

Table of Contents
What are Examples of Data Science in the Industry?
What Does A Data Scientist Do?
What are the Different Roles in Data Science?
What is the Difference between a Data Scientist and a Data Analyst?
What is a Data Science Lifecycle?
What are the Tools Used in Data Science?
What are the Benefits of a Data Science Career?
How to Get Started in Data Science?
Data science is a domain that has gained widespread popularity in tandem with the rapid technological advances and tremendous digitization efforts of recent years.
More likely than not, you would have enjoyed the benefits of data science in your daily lives. Personalized recommendations on e-commerce platforms, optimized routing on GPS navigation apps, and text autocorrect on mobile devices are just some familiar examples of data science in action.
Beyond these famous use cases, data science plays a vital role in virtually all aspects of business operations across every industry.
What is Data Science?
Data science is a multidisciplinary field that combines scientific principles, analytics tools, and statistical algorithms to derive meaningful insights and hidden patterns from data.
It involves a wide range of expertise, such as mathematics, statistics, programming, visualization, IT infrastructure, and data engineering.
Despite all the hype over state-of-the-art machine learning models, the fundamental objective of data science is to use data to create as much business impact as possible, regardless of the complexity of the tools or models involved.
Data science delivers impact by providing insights that businesses can use to make better decisions and build innovative services and products. Business impact can be in the form of identifying new business opportunities, enhancing customer satisfaction, improving operational efficiency, or boosting sales and marketing efforts.
What are Examples of Data Science in the Industry?
The beauty of data science is its industry-agnostic nature and its tremendous potential in delivering business value across any organization. Here are some real-world examples of successful data science projects in major industries.
|
Industry |
Examples |
|
Healthcare |
Machine learning algorithms developed by IBM can accurately interpret chest X-rays at the performance level of resident radiologists |
|
Insurance |
AXA developed a predictive model to replicate pricing decisions, simplifying the underwriting process for customers and allowing underwriters to focus on more complex risks |
|
Financial Services |
Bank of America developed a financial assistant chatbot that allows customers to efficiently perform tasks like searching for transactions and accessing balance information |
|
Sports |
English Premier League teams are leveraging data and technical analysis such as optical tracking to improve on-field performance |
|
Marketing |
Nike uses predictive analytics to improve customer acquisition and retention by identifying the right customers to target |
|
Education |
Carnegie Learning developed an AI-based digital platform that provides personalized and adaptive mathematics learning paths for students |
|
Biology |
AstraZeneca leverages sophisticated computational models for drug discovery to reduce the time needed to discover potential drug candidates |
|
Real Estate |
Zillow built an automated valuation model that harnesses data to produce an accurate estimate of a property’s market value |
|
Cyber Security |
Siemens uses machine learning to detect and counter cyber threats to protect customers from malware, intellectual property theft, and other forms of cybercrime |
|
Supply Chain and Retail |
UPS layers machine learning models into their massive delivery networks so that the routes are optimized to save miles and money |
|
Agriculture |
Bayer uses machine learning to help farmers achieve better harvests through timely insights obtained from data collected from technologies such as remote sensors and drones |
|
Manufacturing |
Micron developed an AI-Auto-Defect Classification system that classifies and identifies wafer defects efficiently at scale. |
|
Government |
The US Department of Defence leverages data science and analytics to build battlefield advantage and enhance senior leader decision support |
|
Consulting Services |
McKinsey uses its in-house data science and analytics capabilities to deliver insight and impact for clients through a wide range of flexible support models |
Who is the Data Scientist?
Data scientists are data practitioners who investigate, extract, and report meaningful insights in the organization’s data. They communicate these insights to non-technical stakeholders and have a good understanding of machine learning workflows and how to tie them back to business applications.
We can better understand the profile of a data scientist by looking at its essential elements.
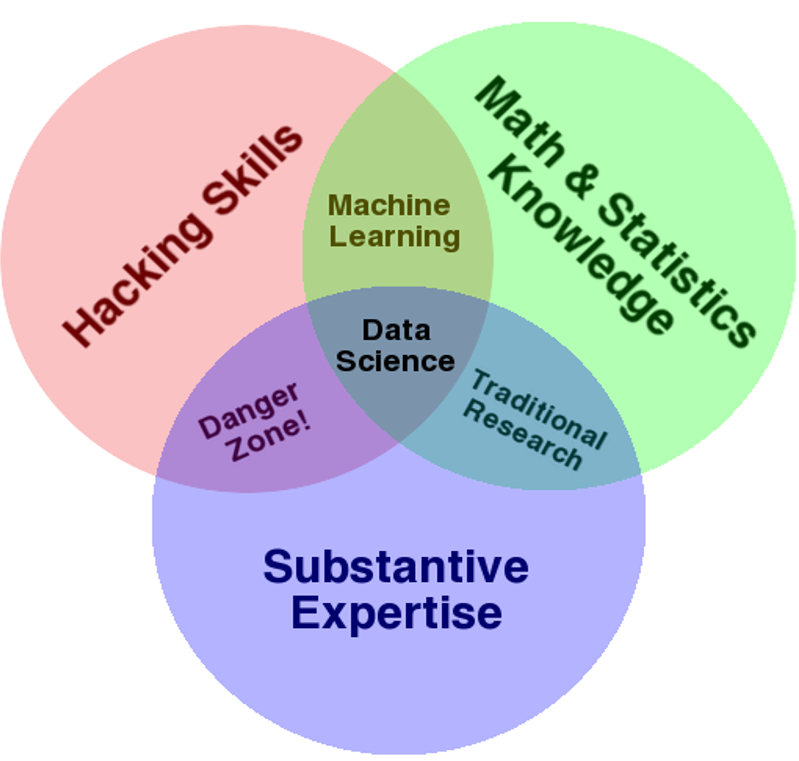
Source: Drew Conway Data Science Venn Diagram
The Venn diagram above illustrates the anatomy of a data scientist.
A data scientist is part computer scientist, part mathematician, and part business domain expert. With these intersecting sets of programming skills, mathematical knowledge, and business expertise, data scientists effectively straddle the business and technological worlds to deliver high impact.
Besides the technical expertise and industry knowledge, data scientists need to be curious and result-oriented while possessing excellent communication skills to present findings to technical and non-technical audiences.
What Does A Data Scientist Do?
Data scientists must first deeply understand the business problem to determine the data and techniques needed. This is done through constant communication and collaboration with business and IT teams in the enterprise.
They are responsible for laying a solid data foundation for robust analytics by developing strategies for capturing, gathering, and cleaning data from different sources. The data scientist then organizes and explores the data before designing, planning, and building solutions for the business problems.
Data scientists also need to communicate their findings to diverse business stakeholders with the effective use of visualizations, dashboards, or reports.
It is important to remember that data scientists do not work alone. Successful data science projects are only possible with a team-based approach involving close partnerships with data engineers, analysts, IT architects, application developers, and business stakeholders to create a refined and holistic solution.
What are the Different Roles in Data Science?
Given that businesses have multiple different functions and that data is expansive and versatile, it is little surprise there are different types of data-related roles in the data science domain. While the data scientist has a prominent position, the data team has other vital members who play an equally crucial role in a data science project.
- Business Analyst: Responsible for tying data insights to actionable results that drive business profitability and efficiency. This is done through deep business domain knowledge and constant communication with the business stakeholders
- Data Analyst: Similar to business analysts, data analysts perform technical analysis to generate actionable insights from data and present these findings and trends to business stakeholders in the form of regular reports and visualizations.
- Data Engineer: Develop, deploy, manage and optimize data pipelines and infrastructure so that the raw data can be extracted, transformed, and loaded in a format ready for downstream analysis and modeling.
- Machine Learning Scientist: Builds and deploys machine learning models into production at scale and monitors the systems’ performance and functionality, focusing on the software engineering aspects that support these models.
- Statistician: Apply statistical methods and models in the design, maintenance, and analysis of experiments (e.g. A/B testing) that meet high statistical rigour
- Data Consumers and Leaders: Consume data insights and analytics to drive data-driven decisions for the business. They are the non-technical stakeholders who have a good grasp of the fundamentals of analytics, and are able to leverage data insights to support decision-making.
What is the Difference between a Data Scientist and a Data Analyst?
On a high level, the two roles of data scientist and data analyst are similar in that they both utilize data to solve business problems. Because of this, there is an overlap of tasks to be performed, such as data querying and cleaning.
The differences between these two roles lie within the specifics of the types of problems they focus on and the tools and techniques they leverage to get to the solution.
Data analysts focus on business intelligence by translating data into actionable insights to support the organization’s strategic decision-making.
Data analysts generate and present these findings in routine reports and dashboards so that stakeholders can be kept updated on the state of the business through key performance indicators. They focus on uncovering insights from hindsight that describes business trends, with the attention aimed at the past and the present.
Data scientists go beyond descriptive analytics by using advanced statistical techniques as part of a forward-looking approach to predict future outcomes. These predictions are then used to drive well-informed business decisions as part of what is described as predictive and prescriptive analytics.
Data scientists design and run different experiments to identify the best models for specific business problems. They also build machine learning pipelines and data products, all with attention aimed at the present and the future.
What is a Data Science Lifecycle?
A data science lifecycle is an iterative series of steps that outline the components of a successful data science project.
Data science projects can involve complicated issues such as messy data, multi-stakeholder involvement, and complex business problems. Therefore the data science lifecycle serves as a pragmatic framework to help teams structure projects effectively.
Because every project and team is unique, there are different versions of the data science lifecycle. Despite that, they all tend to share similar processes in general. As an illustration of how these lifecycles works, we will explore the Team Data Science Process (TDSP), a popular modern data science lifecycle developed and used by Microsoft.
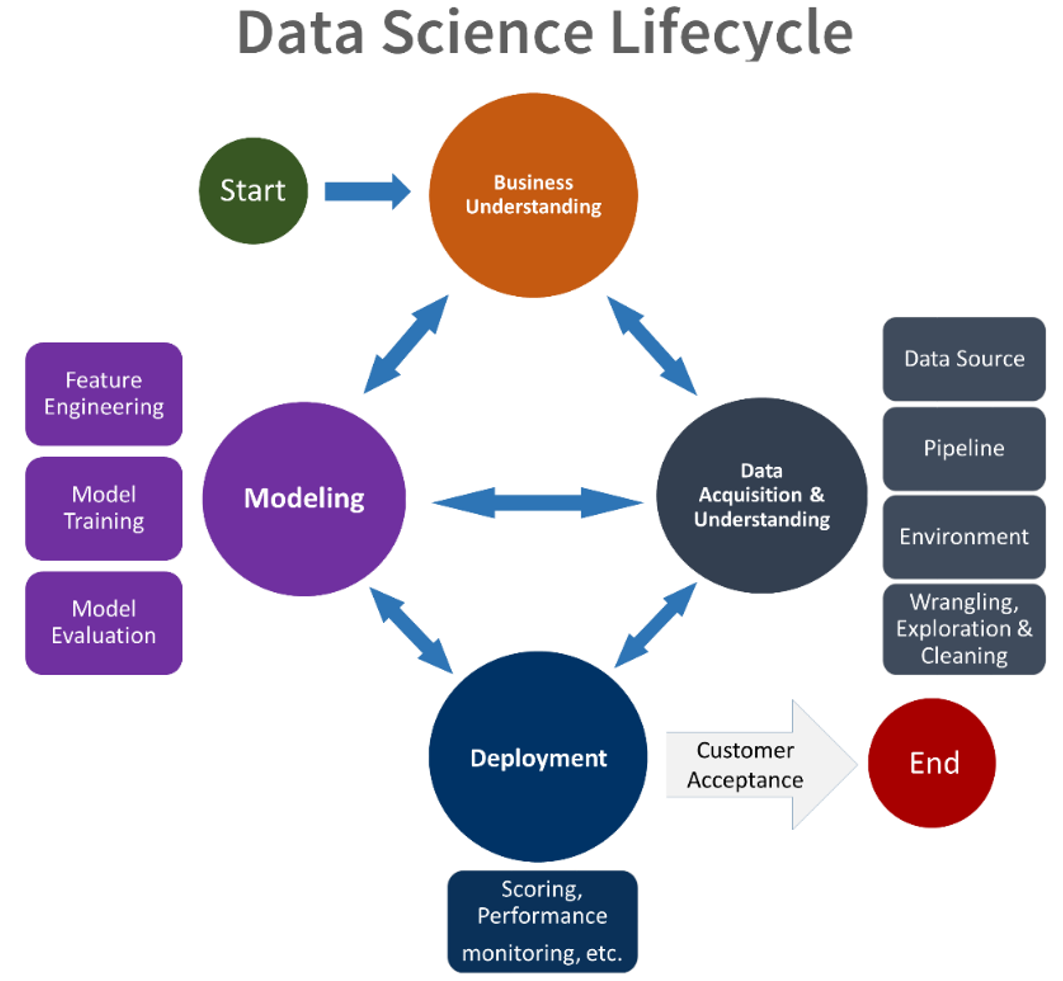
Source: Team Data Science Process (TDSP) by Microsoft
The TDSP lifecycle comprises five stages that are executed iteratively:
- Business Understanding: Define and understand the specific business objectives, project goals, and success metrics while identifying data sources relevant to these objectives
- Data Acquisition and Understanding: Ingest data into an analytic environment, explore data to determine data quality and adequacy, and set up a data pipeline to take in new data or refresh the data regularly
- Modeling: Perform feature engineering of raw data, and carry out model training to identify the machine learning model that answers the business question most accurately based on the success metrics
- Deployment: Operationalize the machine learning model and data pipeline to a production environment for applications to consume and utilize the model predictions
- Customer Acceptance: Confirm that the deployed model and pipeline meets the needs of the business and its customers, and hand the project over to the entity responsible for operations
What are the Tools Used in Data Science?
As seen in the data science lifecycle earlier, many tasks need to be completed in a data science project. Data scientists thus have to use a range of tools (either commercial or open-source) to help them accomplish these objectives.
Programming Languages
While numerous open-source programming languages are used for data science, Python and R are two of the most popular. R is purpose-built for statistical analysis and data mining, while Python is a general-purpose language suited for data-related operations.
Both Python and R are capable of scripting data processing tasks, running complex statistical models, and generating compelling data visualizations. The choice between Python and R depends on the use case since both have their strengths.
R is a good option if the focus is on statistical modeling or advanced visualizations from the data. On the other hand, Python is more suitable if the project entails general-purpose programming tasks or integration with other applications.
Data scientists also use integrated development environments (IDEs) to build projects in these languages. Common IDEs for Python include PyCharm, Spyder, and Jupyter Notebook, while RStudio is the most established one for R.
In the field of big data, Scala is a popular open-source programming language for large-scale data applications and data engineering infrastructure.
In terms of commercial data science tools and languages, SAS and SPSS are the leading legacy products with long histories in the market.
Databases and Analytics Engines
Modern data scientists are expected to interact with large databases, and there are several tools designed for these tasks.
Structured Query Language (SQL) is a query language that allows data scientists to search through large amounts of data and extract information for analysis. It is ideal for handling structured data in relational databases and is considered the universal language of the data industry.
As for non-relational data, NoSQL databases such as MongoDB and Cassandra are prevalent options used in the industry.
Big Data Tools
With increasing volumes of data being collected by enterprises, it is important that data teams can organize, process and store big data efficiently and effectively.
Apache Spark is a popular analytics engine for large-scale processing, letting users perform transformations on big datasets efficiently. It also supports integration with languages such as Python.
In terms of handling convoluted big data pipelines, Airflow is an open-source workflow management tool that allows teams to schedule data pipelines to ensure consistent and reliable data workflows.
Machine Learning and Deep Learning Frameworks
The implementation of machine learning and deep learning techniques allows data scientists to create advanced solutions for businesses.
Python’s scikit-learn and R’s caret are popular libraries that let data scientists readily run a wide range of standard machine learning techniques like classification, and regression.
In terms of deep learning, Python-based Tensorflow and PyTorch are leading frameworks that simplify the building and training of complex neural networks.
Data Visualization
Data insights need to be effectively communicated to the stakeholders for them to make informed business decisions.
Data scientists use data visualization platforms like Tableau and Power BI to generate high-impact data visualizations and stories to drive scalable data-driven decision-making.
Besides these commercial options, open-source packages in Python (e.g., matplotlib, Dash) and R (e.g., ggplot2, shiny) are powerful tools for building compelling visualizations and dashboards.
Cloud Platforms
With an increasing number of companies moving their data to the cloud, data scientists are becoming familiar with the use of these cloud tools and services. Amongst the handful of cloud providers in the market, the three most popular ones are Amazon Web Services, Google Cloud Platform, and Microsoft Azure.
What are the Benefits of a Data Science Career?
The demand for data science talents in the job market continues to be in high demand, coupled with lucrative salaries. The 2021 Burtch Works survey revealed that wages and job opportunities for data scientists continue to rise quickly despite the COVID-19 pandemic.
According to Glassdoor, the data scientist position is considered the second-best job in America in 2021 based on salary, job satisfaction, and the number of job openings. A data scientist can expect to be remunerated with an annual median base salary of around $114,000, significantly higher than the average median income of $51,000.
Besides the impressive financial benefits, a data science career allows you to tackle and solve intriguing challenges across different industries. Because data science skills are highly transferable and in-demand within all sectors, data scientists have golden opportunities to move to various organizations for rich new career experiences.
How to Get Started in Data Science?
The proliferation of online learning resources in recent years means that there has never been an easier time to pick up data science skills. For example, massive open online courses on leading platforms like Coursera, Udemy, and DataCamp provide affordable and flexible ways to learn new data skills.
The downside to this lowered barrier of entry is that beginners tend to get inundated by too many learning options, resulting in confusion and not knowing how to start.
An excellent way to get started is to enrol in the free ‘Understanding Data Science’ course by DataCamp. Through hands-on exercises, participants will learn about different data scientist roles, foundational topics like A/B testing, time series analysis, and machine learning, and how data scientists extract insights from real-world data.
Following up from the introductory course, DataCamp offers comprehensive tracks for learners to continue their learning journey. Students can choose their preferred language (Python, R, or SQL) in the Career Tracks, where essential data skills are taught through systematic, interactive exercises on real-world datasets.
Once one of these career tracks is completed, learners can proceed to the data science certification program to have their new technical skills validated and certified by experts.
blog
A Data Science Roadmap for 2024

Mark Graus
10 min


podcast
Becoming Remarkable with Guy Kawasaki, Author and Chief Evangelist at Canva

Richie Cotton
55 min

podcast
The Venture Mindset with Ilya Strebulaev, Economist Professor at Stanford Graduate School of Business
Richie Cotton
59 min
cheat sheet
LaTeX Cheat Sheet
Richie Cotton
tutorial
Snscrape Tutorial: How to Scrape Social Media with Python

Amberle McKee
8 min
tutorial
AWS Storage Tutorial: A Hands-on Introduction to S3 and EFS

Zoumana Keita
16 min